sqlserver
驱动进程隐藏
用户空间驱动
全文检索
决策树
进程替换
IT难
PC
渲染管线
文件挂载
cisp证书
链接
bypassav
分布式测温系统
cron
App应用程序
OPENCV_DIR
团队开发
枚举
FME
梯度下降
2024/4/11 18:19:02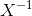
正规方程 Normal Equation
正规方程 Normal Equation 前几篇博客介绍了一些梯度下降的实用技巧,特征缩放(详见http://blog.csdn.net/u012328159/article/details/51030366)和学习率(详见http://blog.csdn.net/u012328159/article/details/51030961ÿ…

【神经网络 基本知识整理】(激活函数) (梯度+梯度下降+梯度消失+梯度爆炸)
神经网络 基本知识整理 激活函数sigmoidtanhsoftmaxRelu 梯度梯度的物理含义梯度下降梯度消失and梯度爆炸 激活函数
我们知道神经网络中前一层与后面一层的连接可以用y wx b表示,这其实就是一个线性表达,即便模型有无数的隐藏层,简化后依旧…

【深度学习】神经网络中 Batch 和 Epoch 之间的区别是什么?我们该如何理解?
文章目录 一、问题的引入1.1 随机梯度下降1.2 主要参数 二、Batch三、Epoch四、两者之间的联系和区别 一、问题的引入
1.1 随机梯度下降
随机梯度下降(Stochastic Gradient Descent,SGD)是一种优化算法,用于在机器学习和深度学习…
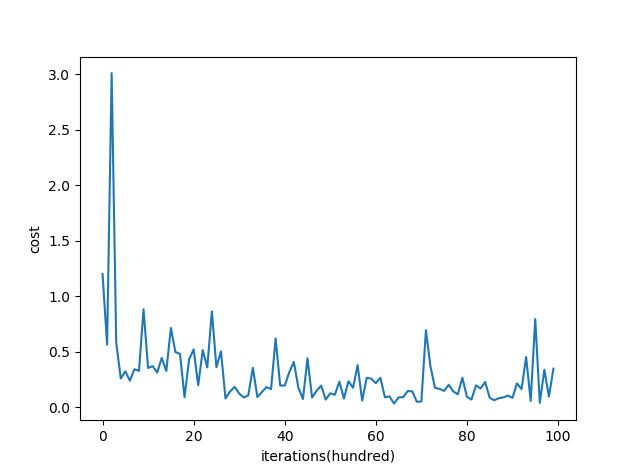
几种梯度下降方法对比(Batch gradient descent、Mini-batch gradient descent 和 stochastic gradient descent)
几种梯度下降方法对比(Batch gradient descent、Mini-batch gradient descent 和 stochastic gradient descent)我们在训练神经网络模型时,最常用的就是梯度下降,这篇博客主要介绍下几种梯度下降的变种(mini-batch gra…
![计算机视觉与深度学习-全连接神经网络-详解梯度下降从BGD到ADAM - [北邮鲁鹏]](https://img-blog.csdnimg.cn/043591377130437e907be8d9fc18275d.gif)
计算机视觉与深度学习-全连接神经网络-详解梯度下降从BGD到ADAM - [北邮鲁鹏]
文章目录 参考文章及视频导言梯度下降的原理、过程一、什么是梯度下降?二、梯度下降的运行过程 批量梯度下降法(BGD)随机梯度下降法(SGD)小批量梯度下降法(MBGD)梯度算法的改进梯度下降算法存在的问题动量法(Momentum)目标改进思想为什么有效动量法还有什么效果&…
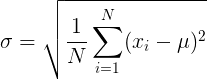
梯度下降实用技巧I之特征缩放 Gradient Descent in practice I - feature scaling
梯度下降实用技巧I之特征缩放 Gradient Descent in practice I - feature scaling 当多个特征的范围差距过大时,代价函数的轮廓图会非常的偏斜,如下图左所示,这会导致梯度下降函数收敛的非常慢。因此需要特征缩放(feature scaling)来解决这个…

梯度下降实用技巧II之学习率 Gradient descent in practice II -- learning rate
梯度下降实用技巧II之学习率 Gradient descent in practice II -- learning rate 梯度下降算法中的学习率(learning rate)很难确定,下面介绍一些寻找的实用技巧。首先看下如何确定你的梯度下降算法正在正常工作:一般是要画出代价函…
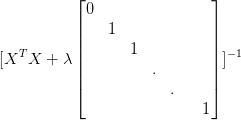
线性回归正则化 regularized linear regression
线性回归正则化regularized linear regression 在前几篇博客中介绍了一元线性回归http://blog.csdn.net/u012328159/article/details/50994095和多元线性回归http://blog.csdn.net/u012328159/article/details/51029695等线性回归的知识,具体请参见本人其他博客。但…
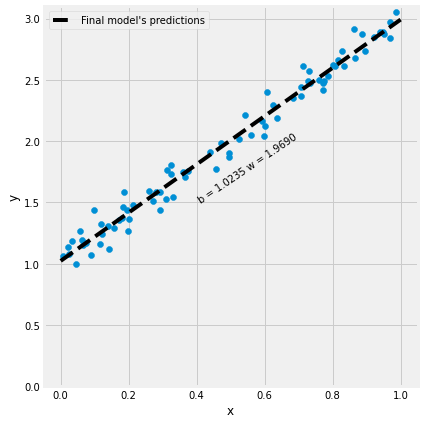
统计软件与数据分析Lesson15----梯度下降(Gradient Descent)过程可视化
梯度下降 Gradient Descent 1.预备知识1.1 什么是机器学习?1.2 几个专业术语 2. 前期准备2.1 加载包2.2 定义模型2.3 生成模拟数据2.4 分割训练集验证集2.5 原始数据可视化 3. 模型训练Step 0: 随机初始化待估参数Step 1: 计算模型预测值Step 2: 计算预测误差&#…
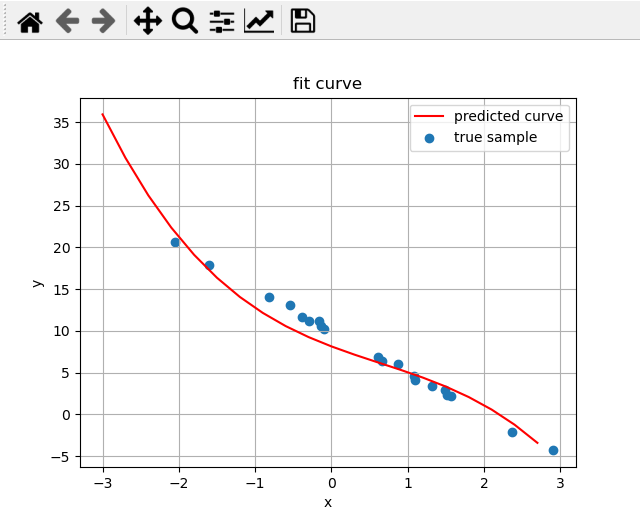
用梯度下降的方式来拟合曲线
文章目录1. 简述2. 理论原理以二次函数为例整体的梯度下降步骤:3. 编码实现初始化权重矩阵计算损失和梯度更新权重4. 结果首先对上一篇文章中的真实数据拟合。测试拟合高次曲线方程数据是2阶的,拟合方程是2阶的数据是4阶的,拟合方程也是4阶的…
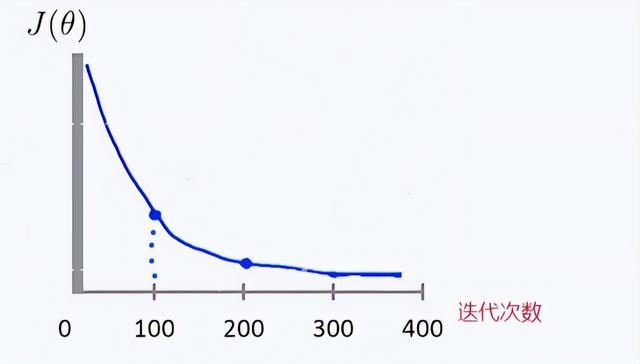
每天五分钟机器学习:如何确定梯度下降中的学习率?
本文重点
学习率是梯度下降算法中的一个重要参数,它控制着每次迭代中参数的更新幅度,因此学习率的大小直接影响着算法的收敛速度和精度。在实际应用中,如何选择合适的学习率是一个非常重要的问题。
手动调整法
最简单的方法是手动调整学习率。我们可以根据经验或者试错的…
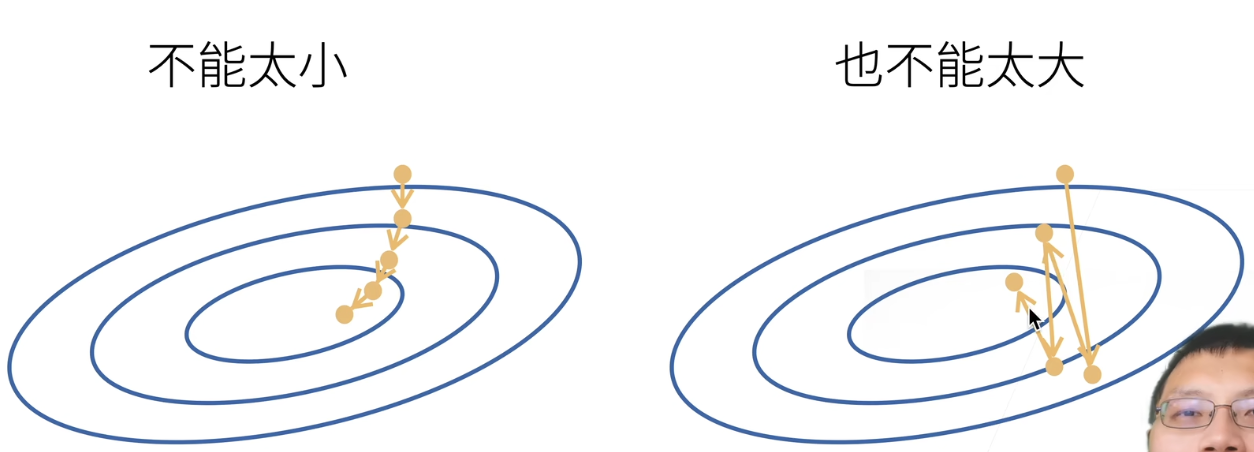
1-2 动手学深度学习v2-基础优化方法-笔记
最常见的算法——梯度下降
当一个模型没有显示解的时候,该怎么办呢?
首先挑选一个参数的随机初始值,可以随便在什么地方都没关系,然后记为 w 0 \pmb{w_{0}} w0在接下来的时刻里面,我们不断的去更新 w 0 \pmb{w_{0}…
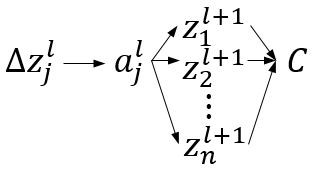
不依靠第三方库(除了numpy)实现一个神经网络
现在各种机器学习、深度学习第三方库都有非常成熟高效的神经网络实现,借助这些第三方库,短短几行代码就能实现一个神经网络。但是对于一个机器学习/深度学习的入门者来说,这些代码封装得太过彻底,往往一行代码就能实现BP算法或者梯…
![深度学习与计算机视觉[CS231N] 学习笔记(3.3):函数优化(梯度下降法)](https://img-blog.csdn.net/20180111125453136?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQva3N3czAyOTI3NTY=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/SouthEast)
深度学习与计算机视觉[CS231N] 学习笔记(3.3):函数优化(梯度下降法)
首先,想象一下这个场景,当我们处在一个山坡上的某一点,我们想要以最近的距离、最短的时间到达坡底,我们应该怎么做呢? 将这个问题抽象出来,就是本文要讨论的梯度下降法。在高数的学习中,我们都…

梯度下降与支持向量机
前言 支持向量机解优化有两种形式,通常采用序列最小化(SMO)算法来解优化,本文总结基于随机梯度下降(SGD)解优化方法。
线性可分SVM 如果数据集是完全线性可分的,可以构造最大硬间隔的线性可分支…

LR的公式推导和过拟合问题解决方案
原文链接 Stanford机器学习课程笔记——LR的公式推导和过拟合问题解决方案 1. Logistic Regression 前面说的单变量线性回归模型和多变量线性回归模型,它们都是线性的回归模型。实际上,很多应用情况下,数据的模型不是一个简单的线性表示就可以…
机器学习笔记 - 了解学习率对神经网络性能的影响
一、简述 深度学习神经网络使用随机梯度下降优化算法进行训练。学习率是一个超参数,它控制每次更新模型权重时响应估计误差而改变模型的程度。学习率值太小可能会导致训练过程过长并可能陷入困境,而值太大可能会导致过快地学习次优权重或训练过程不稳定。 配置神经网络时,学…
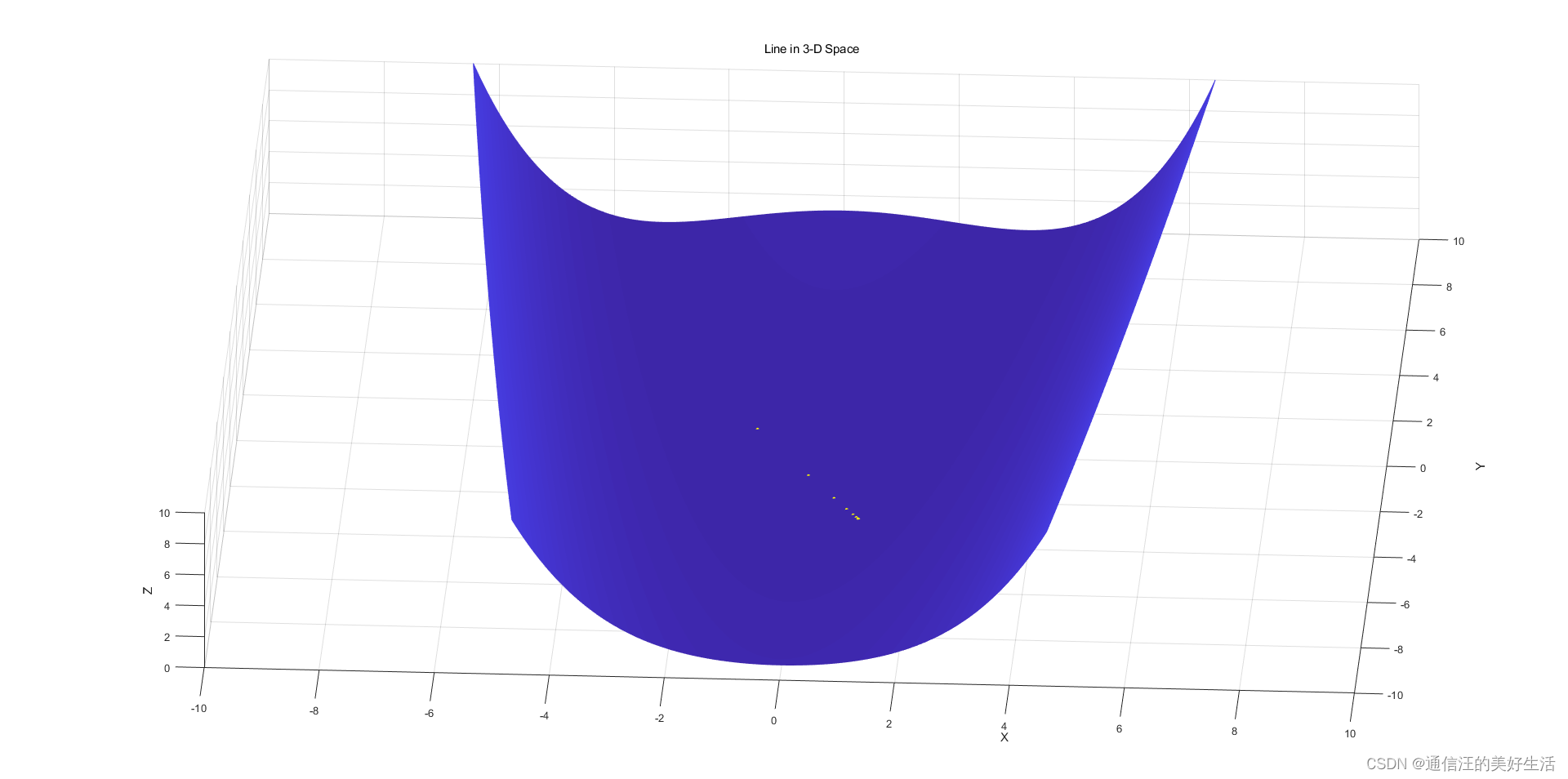
基于非精确线搜索算法三准则实现步长因子的求解
0、前言 朋友请我帮他做一个他们老师留的课堂作业,就自学了一下,我给他做了A准则和G准则的,W准则的留给他自己改了,也没有多难就是换一个判断条件就行了。
一、问题描述 二、要求 三、代码
3.1A准则加回退法
%帮别人做的小作业…
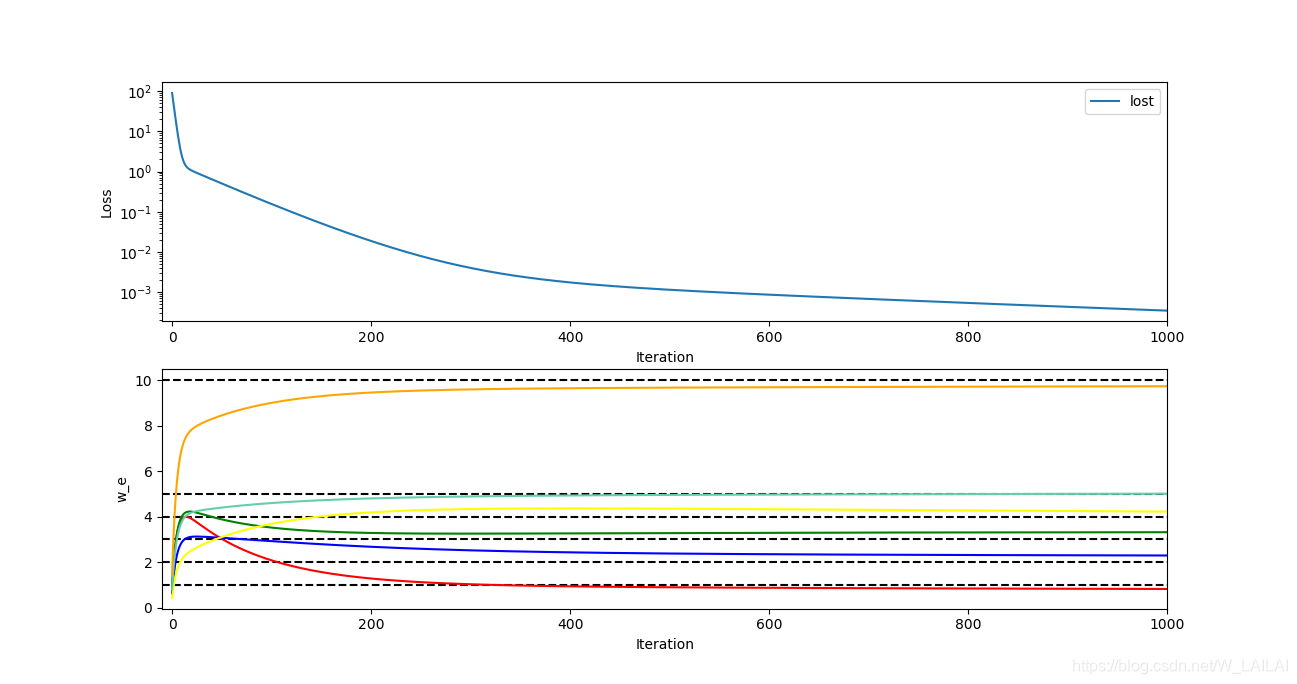
2.线性模型——梯度下降
梯度: 对于一个标量,也就是一维,梯度就是 或者 - 。平面二维向量,梯度也是一个向量,这个向量的方向就是梯度的方向。同理 NNN维,所有梯度也可以沿着变量分解成为相应的梯度分量。
在线性模型——解析解我…

机器学习中梯度下降算法解释为什么梯度方向函数值是下降的
之前学习逆向传播算法对参数的优化,看到了它的原理是梯度下降,所以查了知乎,看到了梯度下降(知乎上资料的链接)的数学原理。梯度就是偏导数构成的一个向量,梯度的模与方向导数最大值一样,指的是…
梯度下降和梯度上升 个人见解
梯度下降和梯度上升是我们学习机器学习必不可缺的一部分。
当学习到梯度下降的时候,你或许会觉得,很有道理。
但是又学习到梯度上升的时候,你可能会觉得,这是什么?什么时候加,什么时候减?
先…
【Machine Learning】Optimization
本笔记基于清华大学《机器学习》的课程讲义梯度下降相关部分,基本为笔者在考试前一两天所作的Cheat Sheet。内容较多,并不详细,主要作为复习和记忆的资料。 Smoothness assumption Upper Bound for ∇ 2 f ( x ) \nabla^2f(x) ∇2f(x): ∥ …
一元线性回归(自写梯度下降法与scikit-learn)
目录 梯度下降法-一元线性回归 一元线性回归-scikit-learn方式实现 梯度下降法-一元线性回归 我自己在网上找的视频课程,里面是通过自写代码来实现梯度下降法&
逻辑斯谛回归(代价函数,梯度下降) logistic regression--cost function and gradient descent
逻辑斯谛回归(代价函数,梯度下降) logistic regression--cost function and gradient descent 对于有m个样本的训练集 ,。在上篇介绍决策边界的时候已经介绍过了在logistic回归中的假设函数为: 。因此我们定义logistic回归的代价函…
梯度下降算法(Gradient Descent)
注意:本文引用自专业人工智能社区Venus AI
更多AI知识请参考原站 ([www.aideeplearning.cn])
算法引言
梯度下降算法,这个在机器学习中非常常见的算法,可以用下山的例子来形象地解释。想象一下,你在一座…

机器学习实践系列之8 - 人眼定位
一. 人眼检测 OpenCV自带的人眼检测,代码及教程都已比较普及,这里不再啰嗦,训练模板直接 load已经训练好的文件: haarcascade_eye_tree_eyeglasses.xml,直接看代码: /* linolzhang 2014.10基于OpenCV的人眼…
![[机器学习]简单线性回归——梯度下降法](https://img-blog.csdnimg.cn/direct/87a9d033ecfa4544a34c1b4261c32d75.png)
[机器学习]简单线性回归——梯度下降法
一.梯度下降法概念 2.代码实现
# 0. 引入依赖
import numpy as np
import matplotlib.pyplot as plt# 1. 导入数据(data.csv)
points np.genfromtxt(data.csv, delimiter,)
points[0,0]# 提取points中的两列数据,分别作为x,y
…
线性回归之向量化 linear regression -- vectorization
线性回归之向量化 linear regression -- vectorization 在线性回归中,通过梯度下降不停的迭代以减少代价函数的值,来拟合出一个效果较好的模型。代价函数如下所示,其中:数据集为m个样本,n个特征。先看,在matlab / octave中&#x…
深度学习-全连接神经网络-详解梯度下降从BGD到ADAM - [北邮鲁鹏]
文章目录 参考文章及视频导言梯度下降的原理、过程一、什么是梯度下降?二、梯度下降的运行过程 批量梯度下降法(BGD)随机梯度下降法(SGD)小批量梯度下降法(MBGD)梯度算法的改进梯度下降算法存在的问题动量法(Momentum)目标改进思想为什么有效动量法还有什么效果&…

人工智能基础_机器学习011_梯度下降概念_梯度下降步骤_函数与导函数求解最优解---人工智能工作笔记0051
然后我们来看一下梯度下降,这里先看一个叫
无约束最优化问题,,值得是从一个问题的所有可能的备选方案中选最优的方案,
我们的知道,我们的正态分布这里,正规的一个正态分布,还有我们的正规方程,他的这个x,是正规的,比如上面画的这个曲线,他的这个x,就是大于0的对吧,而现实生活…

【L2GD】: 无环局部梯度下降
文章链接:Federated Learning of a Mixture of Global and Local Models
发表期刊(会议): ICLR 2021 Conference(机器学习顶会)
往期博客:FLMix: 联邦学习新范式——局部和全局的结合 目录 1.背景介绍2. …
机器学习任务中对数值类型做特征归一化的必要性,《百面机器学习》学习笔记
《百面机器学习》学习笔记:机器学习任务中对数值类型做特征归一化的必要性
需要使用梯度下降进行优化的方法中,一般都需要对数值类型特征进行特征归一化,因为这会影响到梯度下降的速度。为了更好地说明做数据归一化的必要性,首先…
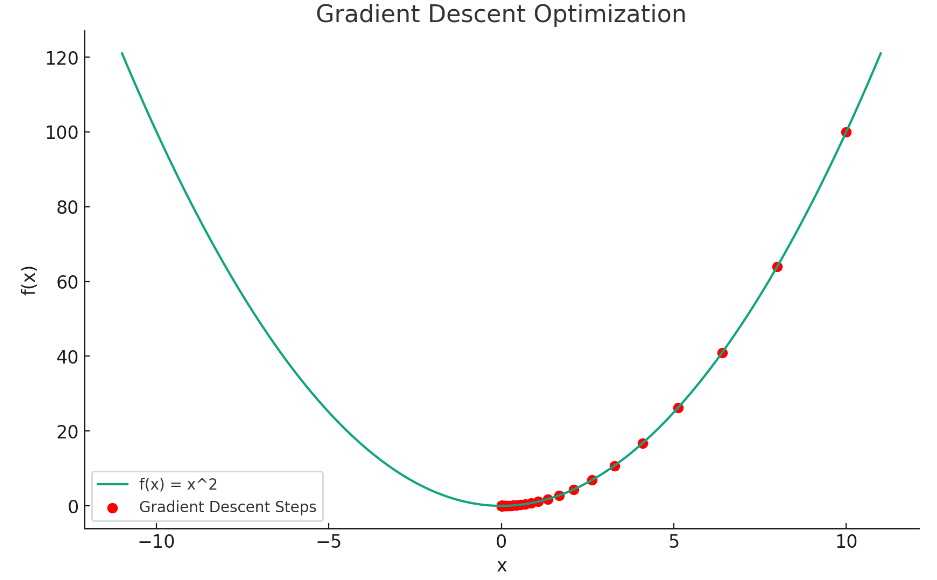
人工智能原理概述 - ChatGPT 背后的故事
大家好,我是比特桃。如果说 2023 年最火的事情是什么,毫无疑问就是由 ChatGPT 所引领的AI浪潮。今年无论是平日的各种媒体、工作中接触到的项目还是生活中大家讨论的热点,都离不开AI。其实对于互联网行业来说,自从深度学习出来后就…
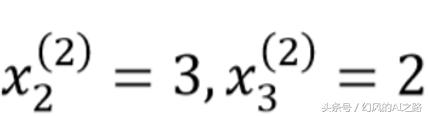
每天五分钟机器学习:构建多特征的线性回归模型
本文重点
在实际应用中,有时候一个单一特征的线性回归模型可能无法很好地解释数据,因此我们可以构建多特征的线性回归模型来提高模型的预测能力。本文还是拿房价问题来举例,来看以下多特征的线性回归模型如何构建?
多特征的数据集
以房价预测为例,现在的样本特征不再是…
神经网络的数学原理——张量运算、梯度下降
张量 神经网络使用的数据经常是存储在Numpy数组中,也称为张量。
一般来说,当前所有机器学习系统都使用张量作为基本数据结构。
张量这一概念的核心在于,它是一个数据容器。它包含的数据几乎总是数值数据,因此它是数字的容器。
…

李宏毅机器学习——学习笔记(2)
Regression
每类特定的参数值构成一个特定的function,所有的参数可取值构成的集合,就是一个function set.loss function的输入是模型的一个特定function, 输出是loss值。
Gradient Descent 梯度下降的方法可以求解任意的loss function&…
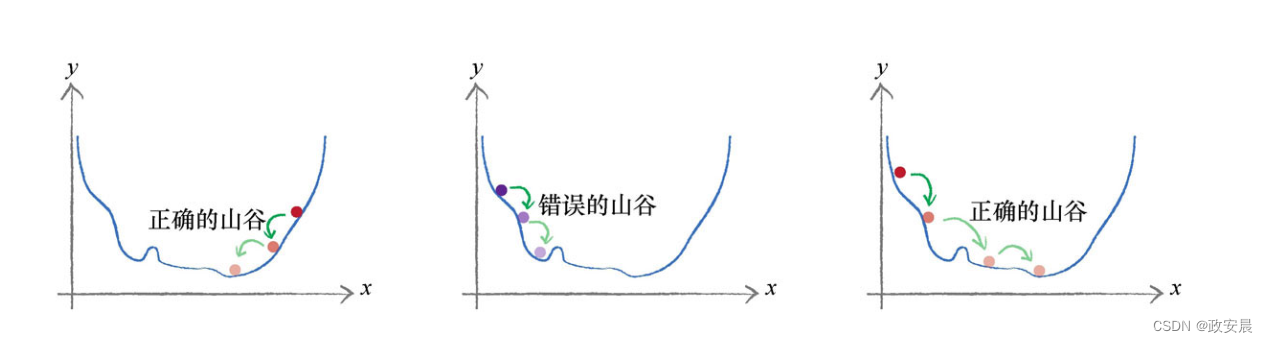
政安晨:【完全零基础】认知人工智能(四)【超级简单】的【机器学习神经网络】—— 权重矩阵
预备
如果小伙伴们第一次看到这篇文章,同时也对这类知识还是稍感陌生的话,可以先看看我这个系列的前三篇文章:
政安晨:【完全零基础】认知人工智能(一)【超级简单】的【机器学习神经网络】 —— 预测机ht…
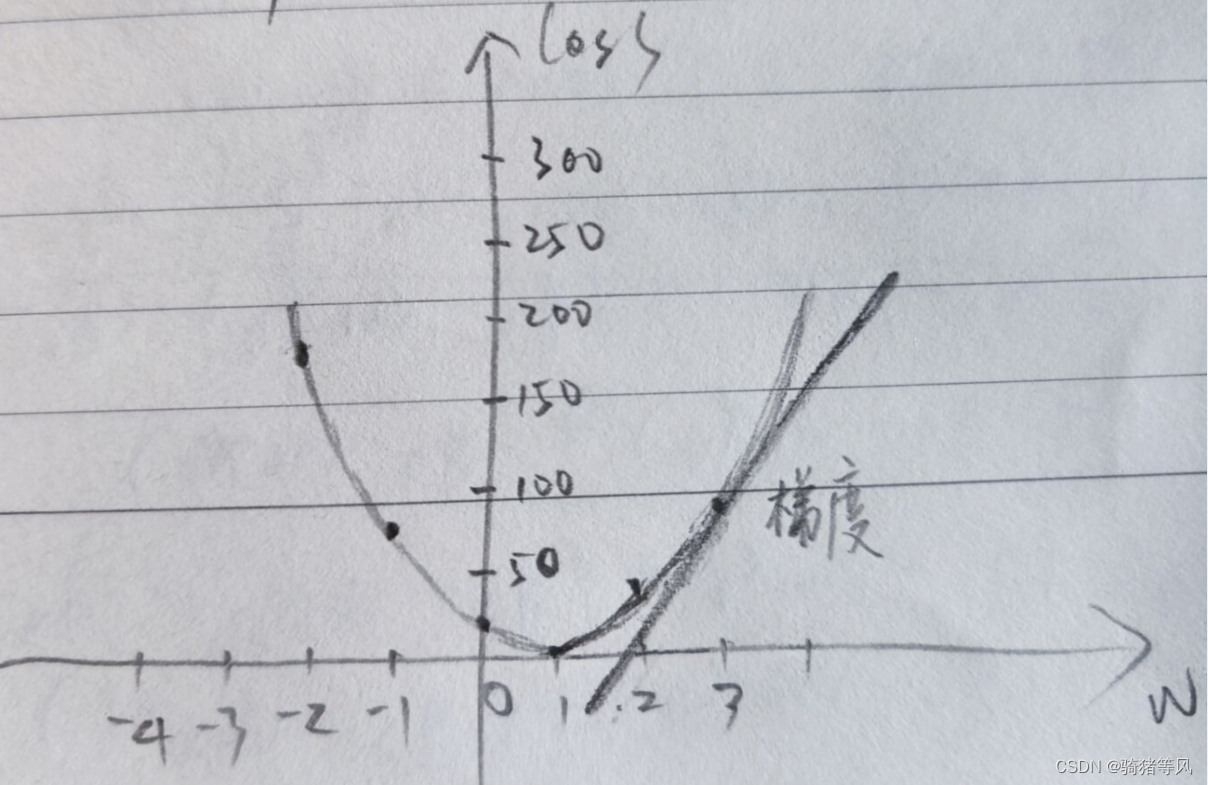
PyTorch官网demo解读——第一个神经网络(3)
上一篇:PyTorch官网demo解读——第一个神经网络(2)-CSDN博客
上一篇文章我们讲解了第一个神经网络的模型,这一篇我们来聊聊梯度下降。
大佬说梯度下降是深度学习的灵魂;梯度是损失函数(代价函数ÿ…
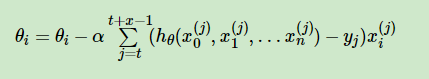
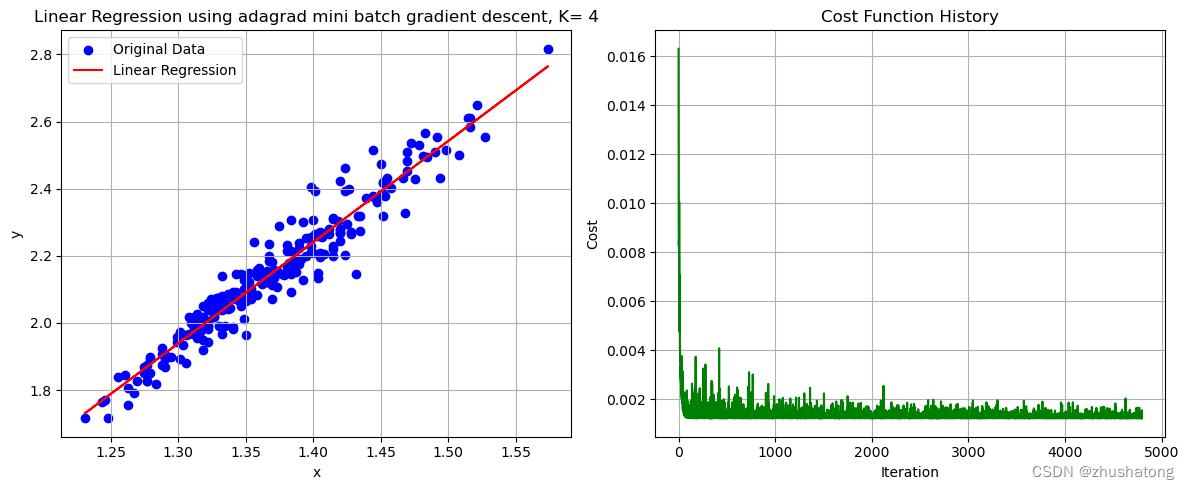
【机器学习】梯度下降法:从底层手写实现线性回归
【机器学习】Building-Linear-Regression-from-Scratch 线性回归 Linear Regression0. 数据的导入与相关预处理0.工具函数1. 批量梯度下降法 Batch Gradient Descent2. 小批量梯度下降法 Mini Batch Gradient Descent(在批量方面进行了改进)3. 自适应梯度…
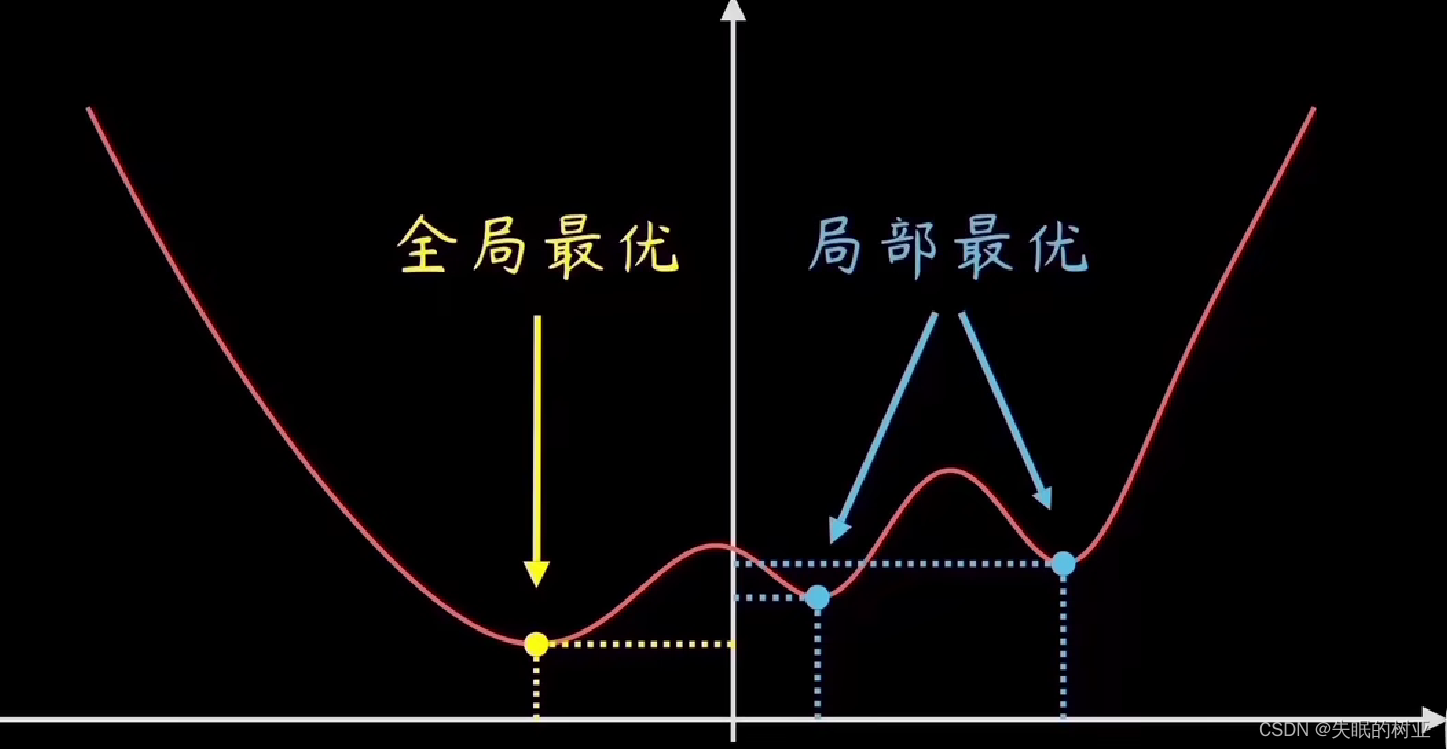

【白话机器学习系列】白话梯度下降
白话梯度下降
梯度下降是机器学习中最常见的优化算法之一。理解它的基本实现是理解所有基于它构建的高级优化算法的基础。 文章目录 优化算法一维梯度下降均方误差梯度下降什么是均方误差单权重双权重三权重三个以上权重 矩阵求导结论 优化算法 在机器学习中,优化是…
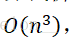
机器学习cs229——(二)线性回归、梯度下降与正规方程组
目录
符号介绍
监督学习的训练过程
线性回归
梯度下降
正规方程组(标准方程组) 符号介绍
在之后的学习中,为了保持一致性,下列符号将经常使用:
m训练样本个数
n特征数量
x输入变量/特征
y输出变量
(x,y)为一…

葫芦书笔记----优化算法
优化算法
实际上,机器学习算法模型表征模型评估优化算法。
其中,优化算法所做的事情就是在模型表征空间中找到模型评估指标最好的模型。
有监督学习的损失函数
有监督学习涉及的损失函数有哪些?请列举并简述它们的特点。 0-1损失 L0−1(f…
![[CS229学习笔记] 2.线性回归及梯度下降](https://img-blog.csdnimg.cn/20191013115911137.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzIyOTQzMzk3,size_16,color_FFFFFF,t_70#pic_center)
[CS229学习笔记] 2.线性回归及梯度下降
本文对应的是吴恩达老师的CS229机器学习的第二课。这节课先介绍了线性回归及其损失函数;然后讲述了两个简单的优化方法,批梯度下降和随机梯度下降;最后推导了矩阵形式的线性回归。 本文出现的图片均来自于coursera上吴恩达老师的机器学习公开…